第2回 ITを支えるコンピュータのしくみ#
この授業で学ぶこと#
この授業では、プログラミングを学ぶ前に知っておきたいコンピュータの背景知識について解説する。
Google Colabとクラウド#
まずは、Google Colabを例に、現在の私たちとコンピュータの関係の一端を紹介しよう。
初回の授業でGoogle Colab上のプログラムを実行したとき、最初のセットアップの時間を除けば一瞬で答えが返ってきたと思う。 ところで、この計算を行った実体は何であるかご存知だろうか。 一見するとGoogle Colabを表示しているブラウザもしくはあなたのPCが計算を実行しているように見えたかもしれない。 しかし実はそうではない。
正解はGoogle Colab上で !curl ipinfo.io というコマンドを実行することで確かめることができる。
このコマンドは、コンピュータの位置情報を返してくれる。
私の環境では、次のような結果が返ってきた。
{
"ip": "34.125.107.162",
"hostname": "162.107.125.34.bc.googleusercontent.com",
"city": "Las Vegas",
"region": "Nevada",
"country": "US",
"loc": "36.1750,-115.1372",
"org": "AS396982 Google LLC",
"postal": "89111",
"timezone": "America/Los_Angeles",
"readme": "https://ipinfo.io/missingauth"
}
このうち ip の横の番号 34.125.107.162 は、IPアドレスというインターネット上での住所を表す。
IPアドレスの番号は、通信を行う全世界のネットワークで一意となるように決められており、電話番号のようなものだと思ってよい(あなたのPC、スマホ、ゲーム機などもインターネット接続時にはIPアドレスが定められている)。
さらに上記の結果からは、IPアドレスに紐づいた地理情報なども確認することができる。
countryにはアメリカ、regionにはネバダ、cityにはラスベガスと書かれている。
実は計算を行った実体は、Google社の所有するアメリカのデータセンターのコンピュータ(写真)だったのである!
つまり、一瞬の間にプログラムの情報を乗せた光信号(一部のケーブルでは電気信号)が日本のあなたのPCを出発し、アメリカのとあるコンピュータに到達し、そして実行結果を乗せて帰ってきたということである。 さらに言えば、太平洋の海底に張り巡らされた海底ケーブルを伝わって通信が行われているという事実は、ロマンに溢れていると感じないだろうか。
Google Colabのように利用者の必要とするコンピュータ資源を、必要なときに必要な量提供する仕組みのことをクラウドと呼ぶ。 私たちがインターネット検索したり、SNSや動画配信サイト、ECサイト、オンラインゲームを利用したりするとき、その背後では、実は多くの場合クラウドが使われており、世界規模での通信が行われている。 クラウドは社会や経済を支える重要なインフラになりつつあり、皆さんも概要は知っておいてほしいので少し説明を加える。
まず基本的な用語として、インターネットなどのネットワークを通じて利用者からのリクエストを受け、それに応じてサービスを提供するコンピュータのことをサーバーという。 従来、企業などがWebサービスを展開するには、専用のサーバーを自社で用意してインターネットに公開するか、または他社からレンタルする必要があった。 レンタルサーバーの場合、通常は1台のサーバーを複数のユーザーで共用する形式であり、利用者ごとに専用の環境が用意されるわけではなかった。
一方、クラウドでは、1台の物理的なコンピュータ上に複数の独立した仮想的なサーバーを作り、それらを利用者ごとに貸し出す仕組みを採用している。 これによりユーザーは、物理的なコンピュータの存在や規模を意識することなく、自分が必要なタイミングで、必要な規模や性能を持ったサーバーを自由に利用できるようになった。 またクラウドを提供する企業(クラウドプロバイダー)の視点では、多くのユーザーにコンピュータ資源を効率よく配分し、コンピュータの稼働率を最大限に高めることで、利益を増やすことが可能となっている。 つまりクラウドとは、物理的なコンピュータの存在を意識せずに、必要な時に自在にコンピュータ資源を活用できるようにすることで、利用者の利便性を向上させ、資源の利用効率を最大化する技術だと言える。
このように私たちは、普段どこかの国のどこかのデータセンター内にあるコンピュータを、特に意識することなく利用している。これが現代社会における私たちとコンピュータの関係の一例である。
コンピュータの性能の進化#
ここまで見てきたようなコンピュータの利用方法というのは、コンピュータを含む各種デバイスの性能の向上により可能になったものである。 ここでは発展のスピード感を知ってもらうため、ムーアの法則について紹介する。
まず、前提知識を簡単に紹介する(どこかで見聞きした単語が多いのではないだろうか)。 コンピュータの中で演算処理を担う頭脳にあたる部品が、プロセッサ 別名 CPU(Central Processing Unit)である。 プロセッサは内部に集積回路、英語名ではIC(Integrated Circuit)を搭載している。 集積回路は、シリコン半導体基板の上にトランジスタなどの回路素子を大量に作り、まとめたものである。 とくにトランジスタは、コンピュータが用いる2進数の1/0を表現するという重要な役割を持っており(電流のon/offのスイッチ機構により実現する)、トランジスタの数が増えるに従いプロセッサの処理能力が向上するという関係がある。
さて本題のムーアの法則は、「集積回路上のトランジスタ数は2年ごとに倍になる」ことを予言したものである。 この法則は1965年に、後にインテルの共同創業者となるゴードン・ムーア氏により提唱された。 以下の図[1]は、実際のトランジスタ数の変化をプロットしたものである。
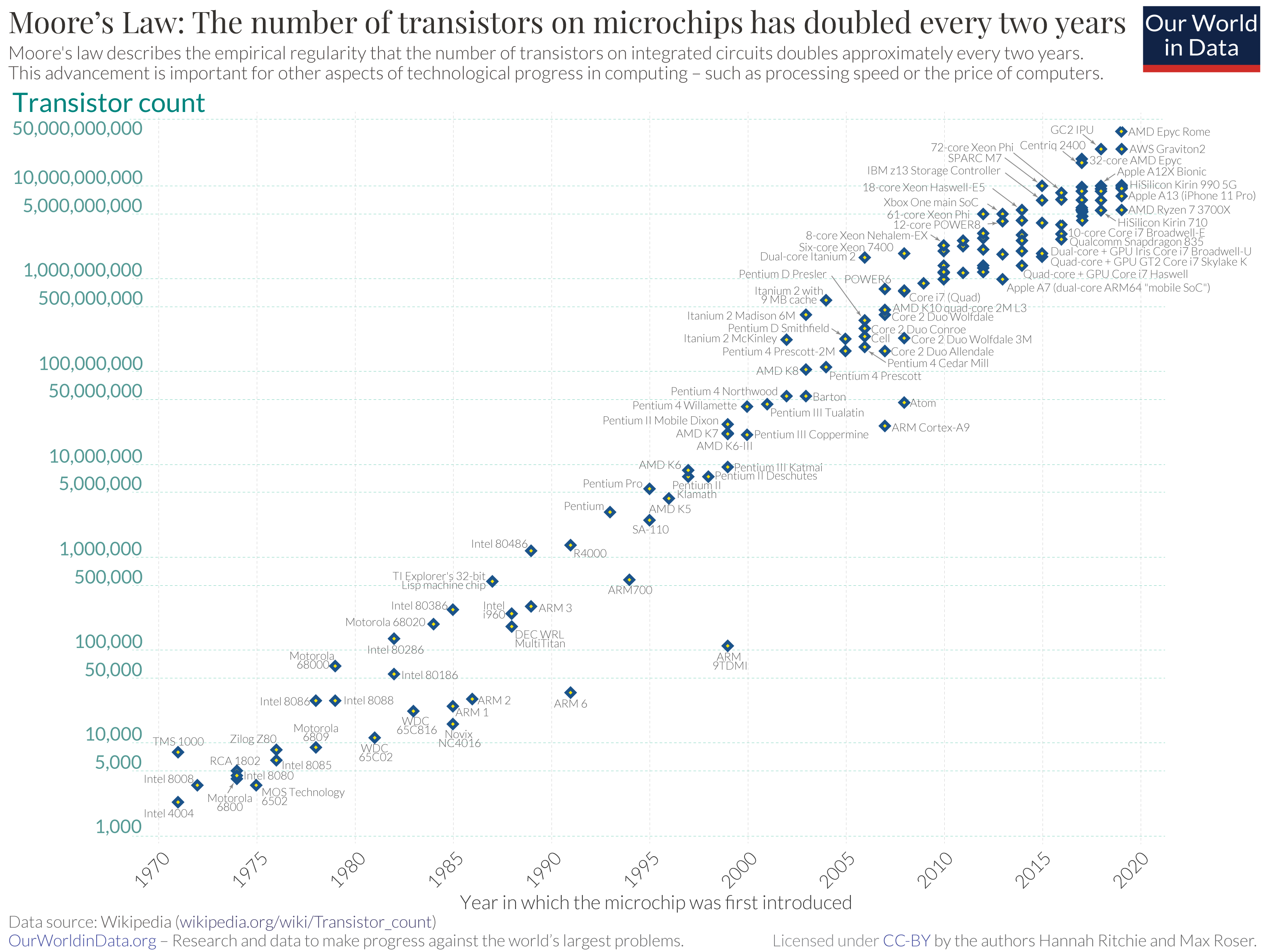
Fig. 2 トランジスタ数の移り変わり#
横軸は発売日、縦軸はトランジスタ数、1つ1つの点はこれまでに発売されたプロセッサ名を表す。 縦軸は対数スケールであることに気をつけよう。 1970年から現在まで、トランジスタ数はおよそ20年ごとに \(2^{10} \simeq 1000\) 倍、つまりムーアの法則通りに増加していることがわかる。
このような変化の仕方は指数的と表現される。 指数的な変化というのは、想像するのが難しいくらい急激な変化である。 実際、この50年で集積回路のトランジスタ数は7桁以上も増えており、驚異的な増加速度である。
ここではプロセッサの処理性能に関係するトランジスタ数についてムーアの法則を紹介した。 同様にメモリやストレージの容量、ネットワーク回線の通信速度など、コンピュータのあらゆる側面の性能が(必ずしも指数的とまでは行かなくても)劇的に向上し続けている。 近年のAIを含むIT技術の進展は、実はこのようなデバイスの飛躍的な進化を原動力としている。
変わらないコンピュータのしくみ#
このようにコンピュータの物理的な性能は、日進月歩で進化している。 しかし、コンピュータの論理的なしくみに着目すると、基本的なところは昔から全く変わっていない。
2進数による情報の表現#
まずコンピュータ上のすべての情報や処理は、細かな要素に分解すると、最終的には1と0という数字の並びや操作に還元できる。 例えば、私たちが普段スマホやパソコンで目にする画像や音楽、動画、文字、数字なども、実際には膨大な数の1/0の並びとして表現されている。
その基本となるのが数字の1/0での表現である。 1/0で表現された数字のことを2進数(バイナリ)という。2進数では2の累乗(2, 4, 8, …)ごとに桁が増える。 一方、私たちが普段使い慣れている数字は10進数である。これは10の累乗(10, 100, 1000, …)ごとに桁が増える記法であった。 0から10までの数字について、対応する2進数の表記は以下のとおりである。
10進数 |
2進数 |
|---|---|
0 |
0 |
1 |
1 |
2 |
10 |
3 |
11 |
4 |
100 |
5 |
101 |
6 |
110 |
7 |
111 |
8 |
1000 |
9 |
1001 |
10 |
1010 |
2進数の桁の重みは右から順に1, 2, 4, 8なので、例えば2進数の1001は \(8\times1 + 4\times0 + 2\times0 + 1\times1 = 9\) より10進数の9に対応する。 3桁の2進数で0〜7までの8種類の数字を表現できていることに注目しよう。 \(n\) 桁の2進数で \(2^n\) 種類の数字を表現できるという点は重要である。 \(2^n\) は先ほど出てきた指数的な関係を表している。 したがって、少ない桁数で想像以上に多くのことを表現することができる。
なおコンピュータの世界では、2進数における1桁分をビット、8桁分をバイトという。 よく出てくる単位なので覚えておこう。
Tip
\(2^n\) の増加速度がいかにすごいかがわかる例として「紙を30回折ったら」というのがある。 紙の厚さを0.1mmとして30回折ると、\(0.1\times 2^{30} {\rm mm}\simeq 10^8 ~{\rm mm} = 100 ~{\rm km}\) よりその厚さはなんと100km近くになる。これは地表から宇宙に到達する厚みである! そう聞くと実際に試してみたくなるかもしれないが、現実には30回折る前に紙は破損してしまうだろう。
次に画像の2進数での表現方法を紹介しよう。 まずフィルムカメラで写真を撮ったときのことを考える。 このときフィルムカメラが行っていることは、被写体の光を集めて感光用の化学物質が塗られたフィルムに当てることで、光の情報を写しとることである。 フィルムカメラで撮られた写真は、光の位置や色をそのまま写しとるという意味でアナログ(連続的)な画像である。
一方で、スマホやパソコンに表示される画像は、光の位置や色についてとびとびの値で表現されたデジタル(離散的)な画像である。 画面の液晶ディスプレイは、ピクセルと呼ばれる小さな点が格子状に並べられてできており、虫眼鏡などで画面を拡大すれば1つ1つのピクセルを確認することができる。 また色も赤、緑、青の光の三原色に分解され、それぞれの色を0〜255までの256段階で表現している。この数値に基づき各ピクセルが発行する仕組みだ。
赤、緑、青の各色の度合いについて256段階の数値で表現しているのは、まさに内部で2進数が使われていることの証左である。 というのも \(2^{8} = 256\) であり、ちょうど1バイトの2進数を使うと無駄なく表現できる範囲の数だからだ。 したがって、赤、緑、青の合わせて3バイトで1つの色を表現していることになる(この表現法をRGBという)。
したがって例えば \(100\times100\) ピクセルの画像であれば \(100\times100\times3\) バイトの2進数で表現される。 単位としてキロバイト(KB)(= 1000バイト)を用いれば、30KBの画像ということである。 ただし実際には、このように単純な方式で保存していることはほとんどなく、さらに圧縮した形式(jpg、pngなど)で保存されているため、パソコン上で容量を調べるともっと小さい値になる。
ここでは数字と画像を例にとって、データの表現方法を説明した。 バイナリレベルに立ち返って考えれば、今のコンピュータも昔のコンピュータも扱っているデータは同じである。 さらに言うと、これらバイナリのデータに対して行える操作も昔から変わっていない。 どのような計算が行えるかという意味では、昔も今も、スマホもパソコンも本質的にはすベて同じ仕組みで動いているのだ。
ソフトウェアのしくみ#
プログラムやデータの総称をソフトウェアという。これはコンピュータの物理的な構成要素であるハードウェアと対比される言葉である。 ここでは、今後の講義内容に関連するソフトウェアのしくみについて、重要なポイントに絞って解説する。
まず、改めての説明になるが、コンピュータに行わせたい処理を記述した命令の集まりをプログラムと呼ぶ。 皆さんがこれから学ぶPythonは、プログラムを記述するためのプログラミング言語の1つである。 プログラミング言語を使って記述したプログラムをソースコード(またはコード)という。 私たちが普段利用しているブラウザや、ワープロソフト、表計算ソフト、画像編集ソフトなどアプリケーションソフトウェア(略してアプリ)は、すべて何かしらのプログラミング言語を使って作られている。 Pythonを学び続けることで原理的にはこのようなソフトウェアを作ることも可能になる。
コンピュータに行わせたい処理には、しばしばハードウェアの操作が含まれる。 このときソフトウェアとハードウェアの間に入り、その操作を仲介しているのがOS(オペレーティングシステム)である。 OSはハードウェアの複雑な詳細を抽象化によって隠し、裸のコンピュータを人間にとって使いやすくする役割を果たしている。 例えば、ハードウェアの基本的な操作はOSの提供するシステムコールと呼ばれる仕組みで実現されており、Pythonもその内部でシステムコールを利用している。 キーボードの入力を読み取る処理一つとっても、OSなしでは非常に複雑な手続きが必要になるが、OSのおかげで単純にシステムコールを呼び出すだけで済む。
次に、Pythonで書いたプログラムがどのようにコンピュータで実行されるのかについて説明する。 プログラムを実行する主体であるプロセッサは、Pythonのソースコードをそのまま理解することはできない。 プロセッサが直接理解できる言語は、 1と0の数字の並びで表される機械語のみである(データだけでなくプログラムも最終的にはバイナリになるのだ!)。
Pythonのソースコードは、以下のような手順で機械語に変換され、実行される。 Pythonのソースコードを実行すると、まずははバイトコードという中間データに変換される。 その後、Pythonの仮想マシンがこのバイトコードを解釈して機械語を生成し、それがプロセッサに渡されて実行されるという仕組みである。
機械語はプロセッサごとに異なるため、同じバイナリでもプロセッサが変わると意味が通じない。 しかし、Pythonのソースコードはプロセッサなどの実行環境に依存せず、どの環境でも同じように書くことができる。 これが可能なのは、Pythonの仮想マシンが環境ごとの違いを吸収しているためである。 つまり、ソースコードやバイトコード自体は環境に依存しないが、仮想マシンが環境に合わせて適切な機械語を生成することで、私たちは環境の差異を気にせずプログラムを作れる。 これもまた抽象化の一つであり、そのおかげで異なる環境へのソフトウェアの移植も容易になっている。
ここではソフトウェアのしくみの重要な一部分を解説した。ソフトウェアでは、さまざまな側面で抽象化が行われており、特に物理的な詳細をユーザーから隠すことが重視されている。 抽象化された論理的な仕組みは余り変化しないため、私たちは頻繁に知識を更新することなく、コンピュータの物理的性能向上の恩恵を享受できるのである。