第8回 データの入れ物#
![]()
この授業で学ぶこと#
第7回の冒頭で説明したように、これまでに学習した文法だけでも、プログラミングで必要なほとんどの処理を実現できる。しかし、これまでの知識だけでは、状況によってはコードが冗長になってしまう場合がある。第8回から第10回にかけては、プログラミングをより効率的かつ簡潔に行うための方法を学ぶ。
今回は、複数のデータを効率よく管理するための基本的なデータ型を学習する。以前に学んだリスト型もその一例だが、それ以外のデータ型も学ぶことで、よりシンプルで分かりやすいコードを書けるようになる。
データの入れ物#
リスト型のようにデータの入れ物の役割を果たす組み込み型として、他に辞書型(dict)、タプル型(tuple)、セット型(set)などがある。 今回はこれらのうち重要性の高いリスト型、辞書型、タプル型について学ぶ。リスト型は改めての説明になるが、第4回の内容より一歩踏み込んで学ぶ。
リスト型#
第4回で学んだ通り、リストはデータを , で区切り、両端を [] で囲うことで作成できる。
x = [1, 2, 3, "four", 5]
インデックスによる要素のアクセス方法を復習しておこう。上の例で "four" や 5 を取り出すには、以下のようにインデックスを指定する。
print(x[3])
print(x[-2])
print(x[4])
print(x[-1])
要素の追加と変更#
今回新たに要素の追加方法を学ぶ。
よく使われるのが要素を末尾に追加する方法で、append() メソッドを用いる。
append() は、引数に渡されたデータをリストの末尾に追加する。
x.append(6)
x
要素を特定の位置に挿入するには insert() メソッドを用いる。insert() は、第一引数にインデックス、第二引数にデータを受け取る。
x.insert(0, "zero")
print(x)
x.insert(2, 1.5)
print(x)
2つのリストを連結するには + 演算子を用いる。
y = x + [6, 7]
y
リストの要素を変更するには代入文を用いる。
x[0] = 0
print(x)
x[3] = '2'
print(x)
リストの要素を削除するにはdel文または pop() メソッドを用いる。
del文は del の後ろに指定した要素を削除する。あとで説明するスライスと組み合わせると、複数の要素をまとめて削除することもできる。
del x[2]
print(x)
del x[6:] #スライス
print(x)
pop() メソッドは引数で指定したインデックスの要素をリストから削除し、その値を戻り値として返す。
elem = x.pop(2)
print(elem)
print(x)
練習1
正の整数 n が与えられるとき、for文と append() メソッドを使って 0 から順に n-1 までの整数を含むリストを作成し、それを print するコードを作成しなさい。

# nの一例 (この例では [1, 2, 3, 4] と出力するのが正しい)
n = 4
# 以下にコードを作成し、以下の部分のみ提出する
y = []
for i in range(n):
pass
print(y)
y = []
for i in range(n):
y.append(i)
print(y)
練習2
正の整数 n が与えられるとき、for文と append() メソッドを使って 1 から順に n までの整数を含むリストを作成し、それを print するコードを作成しなさい。
# nの一例 (この例では [1, 2, 3, 4] と出力するのが正しい)
n = 4
# 以下にコードを作成し、以下の部分のみ提出する
y = []
for i in range(n):
y.append(i+1)
print(y)
練習3
整数を要素とするリスト x が与えられたとき、x 中の偶数のみを含む新しいリスト y を作成し、そのリスト y を print するプログラムを作成しなさい。ただし、リスト y の要素の順番は、x での順番を保持すること。
ヒント: リスト x の要素のうち、偶数という条件を満たすものだけ y に append する。
# xの一例 (この例では [2, 4] と出力するのが正しい)
x = [1, 2, 3, 4, 5]
# 以下にコードを作成し、以下の部分のみ提出する
y = []
for v in x:
pass
y = []
for v in x:
if v % 2 == 0:
y.append(v)
print(y)
スライス#
リストから連続した複数の要素を取り出すために使われるのがスライスである。
整数 i、j を用いてリストに対して [i:j] と要素を指定すると、インデックスが i から j-1 までの要素を取り出すことができる。
i または j を省略することもできる。
[:j] は、インデックスについて最初から j-1 までの要素を取り出す。
[i:] は、インデックスについて i から最後までの要素を取り出す。
また i、j には負のインデックスを指定することもできる。例えば、x[:-1] はリストの末尾の要素だけを除いたすべての要素を取り出す。
以下にサンプルコードと図を示す。
x = [1, 2, 3, "four", 5]
print(x[1:4])
print(x[:4])
print(x[:-1])
print(x[1:])
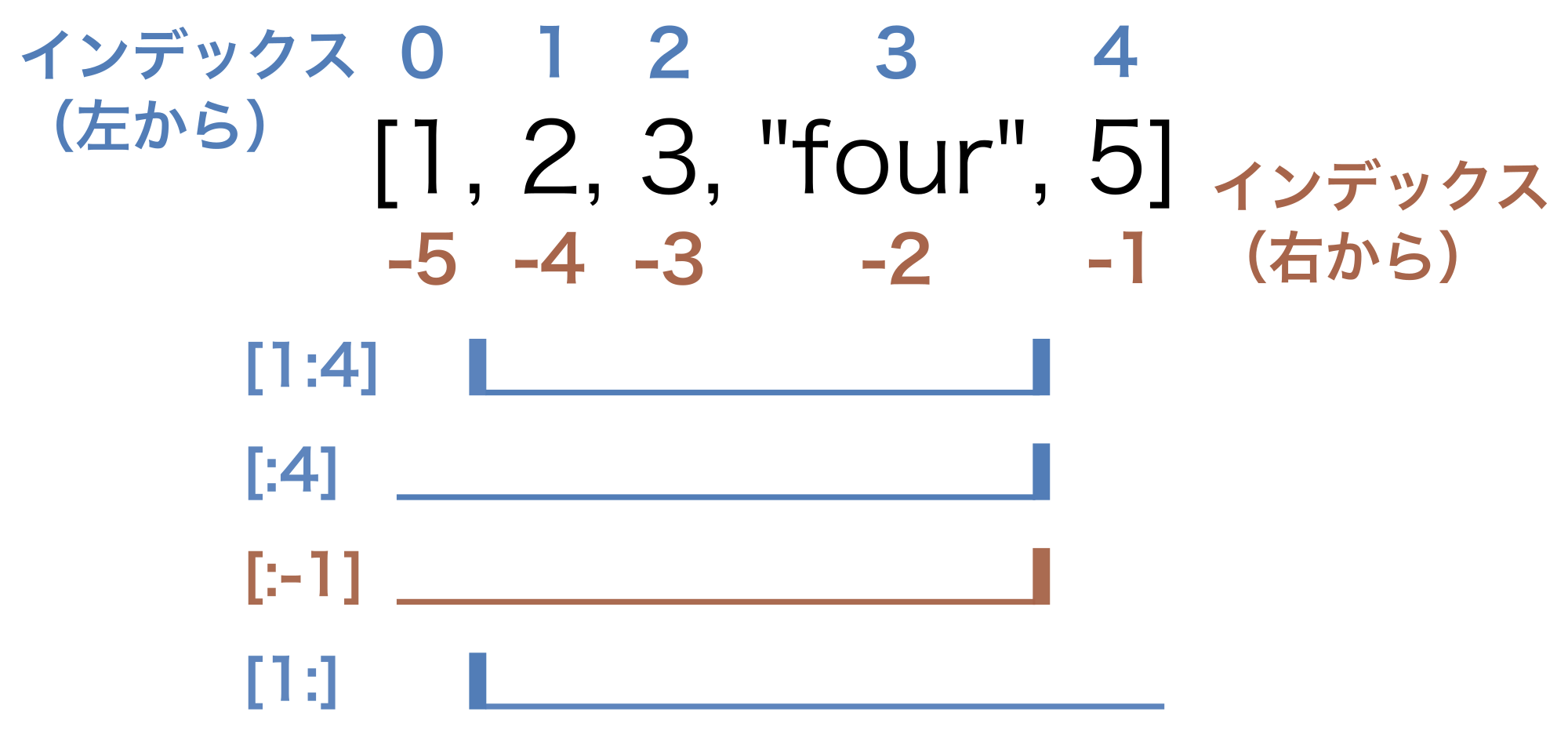
Fig. 15 スライスとインデックスの関係#
練習4
要素数が2以上のリスト x が与えられるとき、先頭と末尾の要素を除いたリストを作り、print するコードを作成しなさい。
# xの一例 (この例では [2, 3, 4] と出力するのが正しい)
x = [1, 2, 3, 4, 5]
# 以下にコードを作成し、以下の部分のみ提出する
print(x[1:-1])
辞書型#
リストでは0から始まる整数インデックスをもとに要素にアクセスした。 辞書型は、自由に設定したキー(key)をもとに要素にアクセスできるようにしたデータ型である。 辞書型では要素のことを値(value)と呼ぶ。
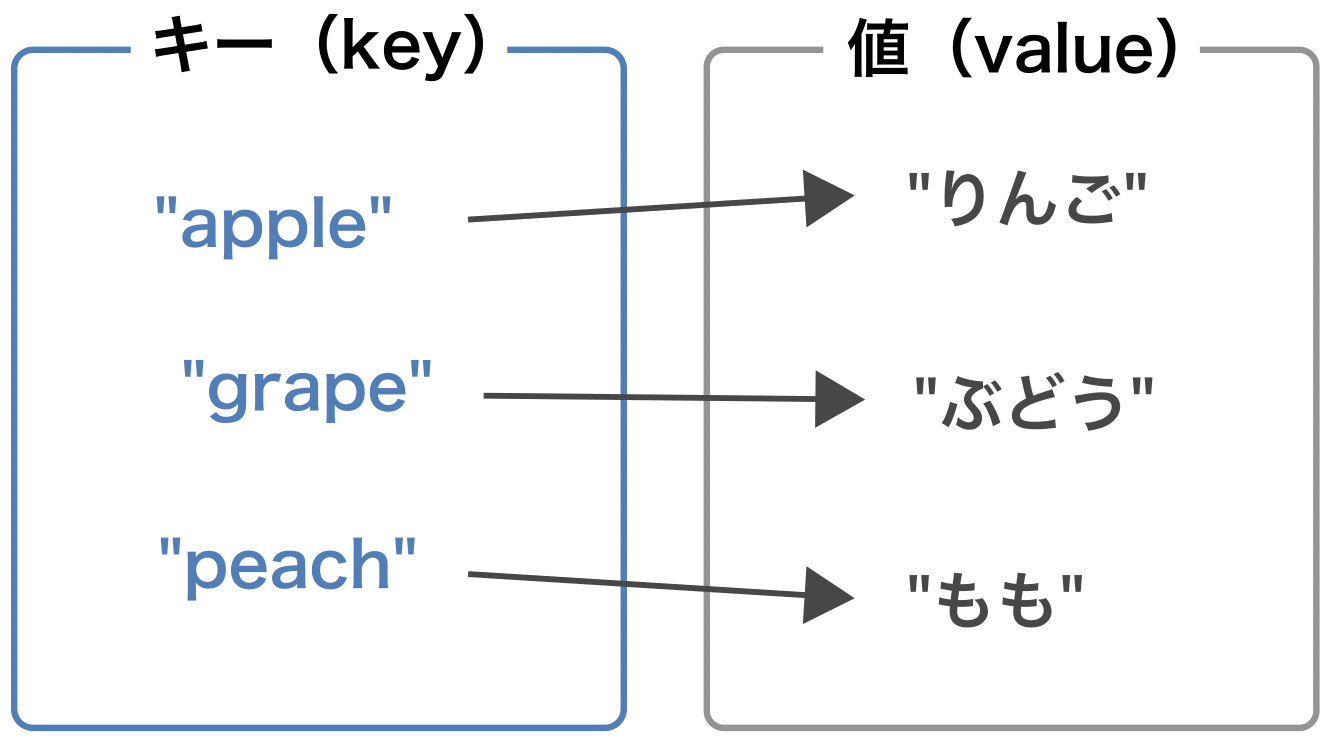
Fig. 16 辞書型#
辞書は、: を使ってキーと値のペアを指定し、各ペアを , で区切って、両端を {} で囲うことで作成できる。
x = {"apple": "りんご", "grape": "ぶどう", "peach": "もも"}
type(x)
リストと同様、値には [] を使ってアクセスできる。
print(x["apple"])
print(x["grape"])
リストと同様、存在しないキーを指定するとエラーになる。 キーが存在するかは、in演算子により確かめることができる。 したがって、キーが存在するかわからない場合は、if文で確かめてからアクセスする必要がある。
if "cherry" in x:
print(x["cherry"])
値にはどのようなデータ型も使用できる。 ただし、キーにはイミュータブル(変更不可能)なデータ型しか使用できない。 これはキーが途中で変わらないことを保証するためである。
発展的な話題: ミュータブルとイミュータブル
データ型には、作成したあとでも中身を変更できるものと、変更できないものがある。 要素の変更・追加・削除ができるものをミュータブル(mutable)、変更できないものをイミュータブル(immutable) という。
分類 |
データ型 |
特徴 |
|---|---|---|
ミュータブル |
リスト、辞書 |
要素を変更・追加・削除できる |
イミュータブル |
整数、浮動小数点数、文字列、真偽値、タプル |
作成後の変更はできない |
リストや辞書はミュータブルなデータ型である。
実際、どちらも [] を使った代入文により要素を変更することができる。
一方で整数、浮動小数点数、文字列、真偽値、タプルはイミュータブルなデータ型である。 例えば、次のようなコードを実行したとする。
x = 1 x = 2 # 新たな整数オブジェクト2を作成し、xに再代入(元の1は変化しない)
このとき x = 2 は、新しいオブジェクト 2 を作成して変数 x に代入しているのであって、元のオブジェクト 1 の値を変更しているわけではない。
これらの区別は、次のような例で重要になる。
# ケース1 x = 1 y = x x = 2 print(y) # 1が出力される
# ケース2 x = [0, 1] y = x x[0] = 2 print(y) # [2, 1]が出力される
どちらのケースでも、y = x と書いた直後は変数 x と y は同じオブジェクトを指している。しかし、ケース1において x = 2 は新しいオブジェクトを x に代入しているので、変数 y の値に影響はない。一方、ケース2において x[0] = 2 はオブジェクトを変更しているので、変数 y の中身も変化してしまう。
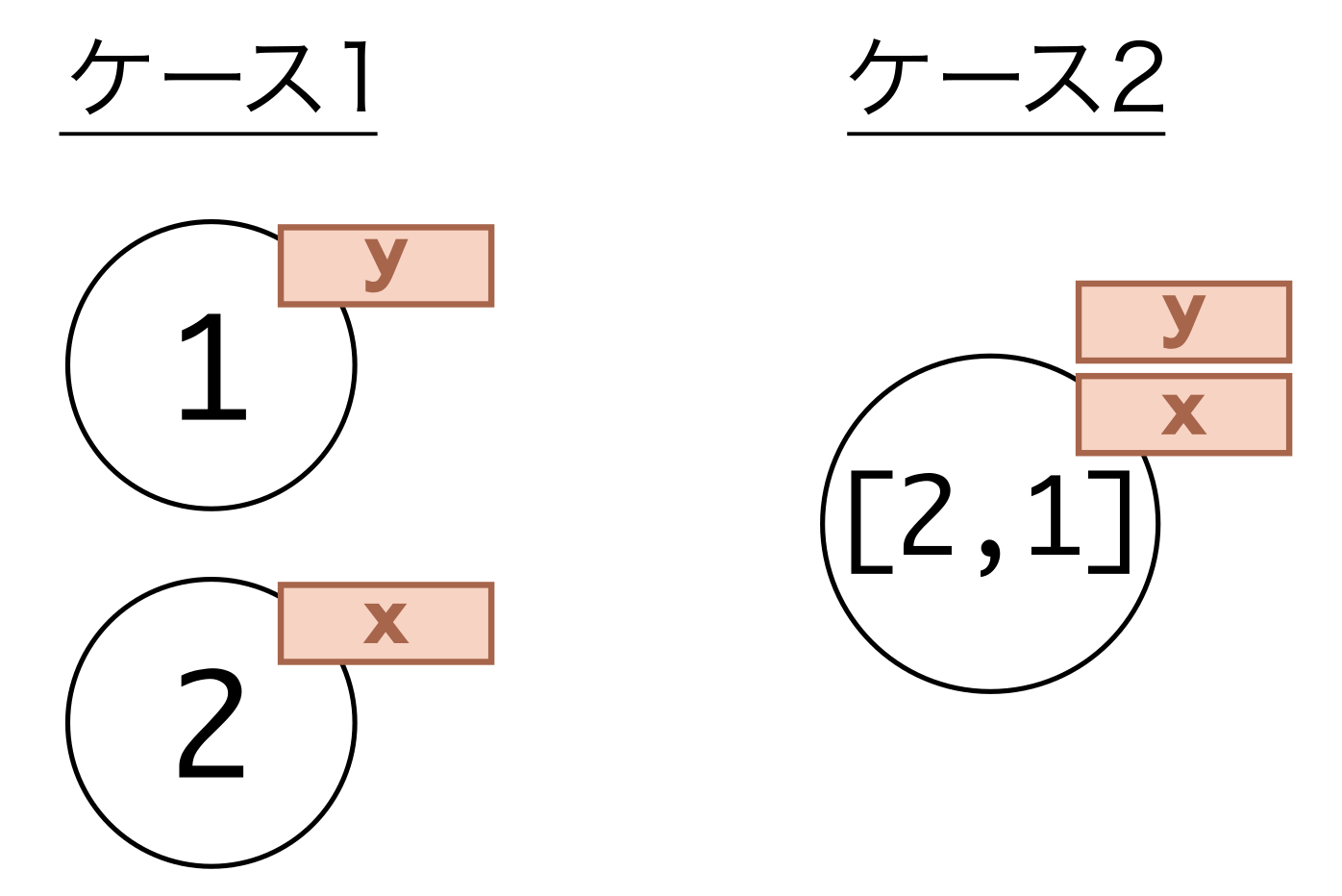
Fig. 17 変数のイメージ#
要素の追加と変更#
辞書に要素を追加したり変更したりするには、代入文を用いる。
x["cherry"] = "さくらんぼ" # 追加するときには、存在しないキーを指定してもエラーにならない
x["grape"] = "ブドウ"
x
辞書から要素を削除するには、del文を用いる。
del x["grape"]
x
ループ処理#
リストと同様、辞書の中身を一つずつ取り出して何らかの処理を行う機会は多い。 辞書型では、for文を使うと変数にキーが順に代入されるので、以下のようにループ処理を書くことができる。
for key in x: # keyにはキーが順に代入される
print(key)
print(x[key])
辞書の要素をループで処理するときは、キーと値を両方取得できる items() メソッドを利用する方法もある。
for key, value in x.items():
print(key)
print(value)
この方法はキーと値を同時に処理したい場合に便利である。
練習5
辞書 x が与えられるとき、値を順に print するコードを作成しなさい。
# xの一例 (この例では "りんご"、"ぶどう"、"もも" と順に出力するのが正しい)
x = {"apple": "りんご", "grape": "ぶどう", "peach": "もも"}
# 以下にコードを作成し、以下の部分のみ提出する
for k in x:
print(x[k])
別解
for k, v in x.items():
print(v)
練習6
値が数値である辞書 x が与えられるとき、全ての値の合計を求めて print するコードを作成しなさい。
# xの一例 (この例では 4 と出力するのが正しい)
x = {'a': 1, 'b': 1, 'c': 2}
# 以下にコードを作成し、以下の部分のみ提出する
total = 0
for k in x:
total += x[k]
print(total)
別解
total = 0
for k, v in x.items():
total += v
print(total)
タプル型#
タプル型は、リスト型をイミュータブルにしたデータ型である。データを , で区切り、両端を () で囲うことで作成できる。
リストと異なる点として、要素数が1つの場合も (2,) のように , で終わる必要がある(そうしないと整数と区別できないため)。
a = (1, 2, 3, 4, 5)
b = (2,)
type(b)
c = (2) # これは整数の2
type(c)
要素のアクセス方法やループ処理の方法など、使い方の多くはリストと同じである。
print(a[2])
print(a[4])
print(a[-1])
for v in a:
print(v)
イミュータブルなデータ型なので、値を変更しようとするとエラーになる。
a[2] = "two"
タプルのリストにない利点として、例えば辞書のキーとして使える点が挙げられる。
x = {(5,3): 15, (2,4): 8}
x = {[5,3]: 15, [2,4]: 8} # リストはミュータブルなので、キーとして使用できない