第12回 表データの処理#
![]()
この授業で学ぶこと#
今回は表データの処理をテーマに、Pandasという表データ解析ライブラリの基本的な使い方を学ぶ。データサイエンスの分野では、表データを扱うことが多いため、Pandasに慣れておくことは重要である。
また、ファイルの入出力の方法についても学ぶ。これまではPythonプログラムの中で完結する処理を扱ってきたが、ファイルの入出力を学ぶことで、パソコン上のデータをプログラムで自由に読み書きできるようになり、実行結果を永続的に保存できるようになるなど、プログラミングの活用範囲が一段と広がる。
Pandas入門#
Pythonでは、表形式のデータ(テーブルデータ)を扱うのにPandasというライブラリがよく用いられる。
Pandasを使うには、pandasモジュールをimportする。import pandas as pd として pd という省略名をつけながらインポートするのが慣例となっている。
ここでは説明のため、seabornというライブラリにサンプルとして用意されているdiamondsというテーブルデータを使用する(データの説明はこちら)。load_dataset() 関数によりサンプルのテーブルデータを取得できる。このようなデータの集まりのことをデータセットという。
import pandas as pd
import numpy as np
import seaborn as sns
df = sns.load_dataset("diamonds")
データフレーム#
Pandasにおいてテーブルデータのことをデータフレーム(DataFrame)という。
データフレームの持つ head() メソッドにより、先頭から5件のデータを表示することができる。
head(10) のように引数に整数を渡すことで、その件数だけデータを表示することもできる。
type(df)
df.head()
データフレームは、2次元配列の行方向と列方向にラベルがついたものと捉えることができる。行方向のラベルのことをインデックス(index)、列方向のラベルのことをカラム(column)という。リストや配列とは異なり、データフレームのインデックスは0始まりの連続した整数とは限らない。インデックスとカラムの値を指定して、要素にアクセスするには loc を使って次のように書く。
df.loc[0, "carat"]
二次元配列と同じように、左上からの順番(0始まりの連続した整数)をもとに要素にアクセスするには iloc を使って次のように書く。
df.iloc[0, 0]
データフレームは2次元配列と相互に変換することができる。データフレームから2次元配列を取得するには、values 属性にアクセスすればよい。
array = df.values
array
逆に2次元配列からデータフレームを作成するには次のように書く。
df2 = pd.DataFrame(array)
df2.head()
カラムのデフォルト値は0始まりの整数である。データフレームの作成時にカラムを設定するには、次のように書く。
df2 = pd.DataFrame(array, columns=["carat", "cut", "color", "clarity", "depth", "table", "price", "x", "y", "z"])
df2.head()
シリーズ#
データフレームは2次元配列に行ラベル・列ラベルをつけたものであった。 Pandasには、1次元配列に行ラベルをつけたデータ型も用意されており、シリーズ(Series)という。
データフレームに対してカラムの値を [] で指定すると、その列のデータをシリーズとして取得できる。
s = df["carat"]
type(s)
s.head()
要素にアクセスするには loc または iloc を使う。
s.loc[0]
s.iloc[0]
シリーズは1次元配列と相互に変換することができる。シリーズから1次元配列を取得するには、values 属性にアクセスすればよい。
array = s.values
array
逆に1次元配列からシリーズを作成するには次のように書く。
s2 = pd.Series(array)
s2.head()
テーブル操作#
データフレームを使うと、テーブルデータでよく行われる操作を簡単に実現することができる。データフレーム上でテーブルデータを加工し、加工したテーブルデータの値を配列として取得して、Matplotlibなど他のライブラリに渡すというのがよくある使い方である。以下にいくつかの操作を紹介する。
ソート#
sort_values() メソッドにより、引数に渡した列を基準にソートすることができる。デフォルトでは昇順にソートする。ソートした結果のデータフレームが戻り値として返されるので、以下のコードではそれを変数 df に再代入している。
df = df.sort_values("carat")
df.head()
降順にソートしたい場合は、引数に ascending=False を指定する。
df = df.sort_values("carat", ascending=False)
df.head()
フィルタリング#
テーブルデータの中から特定の条件を満たす行を抽出することをフィルタリングという。
フィルタリングを行うには、どのインデックスの行を抽出するかをブール型で表したシリーズを loc で指定する。例えば、cut の種類が Premium の行を抽出したいとしよう。このとき cut の種類が Premium かどうかを表すシリーズを次のように作成できる。これをマスクという。
mask = (df["cut"] == "Premium")
mask
このシリーズを locで指定することで、データフレームから cut の種類が Premium の行のみ抽出することができる。
df_premium = df.loc[mask]
df_premium.head()
複数の条件を指定するには、& や | を使う。それぞれの意味はブール型における and と or と同じである。例えば、cut の種類が Premium かつ price が 1000 より大きい行は以下のように抽出できる。
mask = (df["cut"] == "Premium") & (df["price"] > 1000)
df_premium_1000 = df.loc[mask]
df_premium_1000.head()
列の演算#
シリーズは、配列と同様に各種演算を行うことができる。またデータフレームの列の追加や更新は代入文により行うことができる。
例えば、x、y、z の総和を求めて、その結果を sum という列として保持するには、以下のように書く。
df["sum"] = df["x"] + df["y"] + df["z"]
df.head()
例えば、price の対数を計算して price_log という列として保持するには、以下のように書く。
このようにデータが数値の列に対して、NumPyの関数を適用することも可能である。
df["price_log"] = np.log(df["price"])
df.head()
練習1
diamondsデータセットから、カット("cut")が "Ideal" のデータのみを抽出し、そのデータにおける価格の平均、カラットの平均を求めなさい。
ヒント:平均値は シリーズ.mean() でも求められるし、np.mean() 関数を使って求めてもよい。
mask = (df["cut"] == "Ideal") df_ideal = df.loc[mask] print(df_ideal["price"].mean()) print(df_ideal["carat"].mean())
練習2
diamondsデータセットにおいて価格("price")の最も高い5件と最も低い5件のデータを表示しなさい。
df = df.sort_values("price") # 引数にascending=Falseをつけると価格の高い5件が見られる
df.head()
欠損値#
テーブルデータを調べていると NaN という値を見かけることがある。これは Not a Number の略で欠損値と呼ばれる。
例として (0, 0) 要素に None を代入して、あえて NaN を含むデータを作成してみよう。pandasでは None のほか float("nan")、np.nan なども欠損値と見なされる。以下では、もとのデータフレームは上書きしないように copy() メソッドによりコピーしたデータフレームを使って説明する[1]。
df_tmp = df.copy()
df_tmp.iloc[0, 0] = None
df_tmp.head()
特定の列の各行が欠損値であるかを表すマスクは、isnull() メソッドにより作成できる。
mask = df_tmp["carat"].isnull()
df_tmp[mask].head()
分析によっては、欠損値が邪魔になることがある。このときの対処法としては、欠損値を含む行または列を削除する、または代表値で置き換えるなどの方法がある。
欠損値を含む行を削除するには、以下のように書く。
df_dropna = df_tmp.dropna()
df_dropna.head()
欠損値を全体の平均値で置き換えるには、以下のように書く。
mean = df_tmp["carat"].mean() # カラットの平均値
df_tmp["carat"] = df_tmp["carat"].fillna(mean)
df_tmp.head()
ファイルの入出力#
Pandasから話題を変えて、この節ではファイルの入出力について学ぶ。
準備#
Google Colab上でファイルを読めるようにするために、最初にファイルをアップロードする必要がある。
サンプルファイル sample.csv をToyoNet-ACEの授業ページに用意している。sample.csv を授業ページからダウンロードしたあと、「エクスプローラー」を開いて「ダウンロード」の項目を見に行くと、そこにファイルがあるはずである。それを以下の手順でGoogle Colabにアップロードしよう。
Google Colabのサイドメニューのフォルダマークをクリックし、サイドメニュー上に sample.csv ファイルをドラッグ&ドロップする。人によっては写真よりフォルダがたくさん表示されているかもしれないが、その場合は content フォルダ以下にアップロードする。
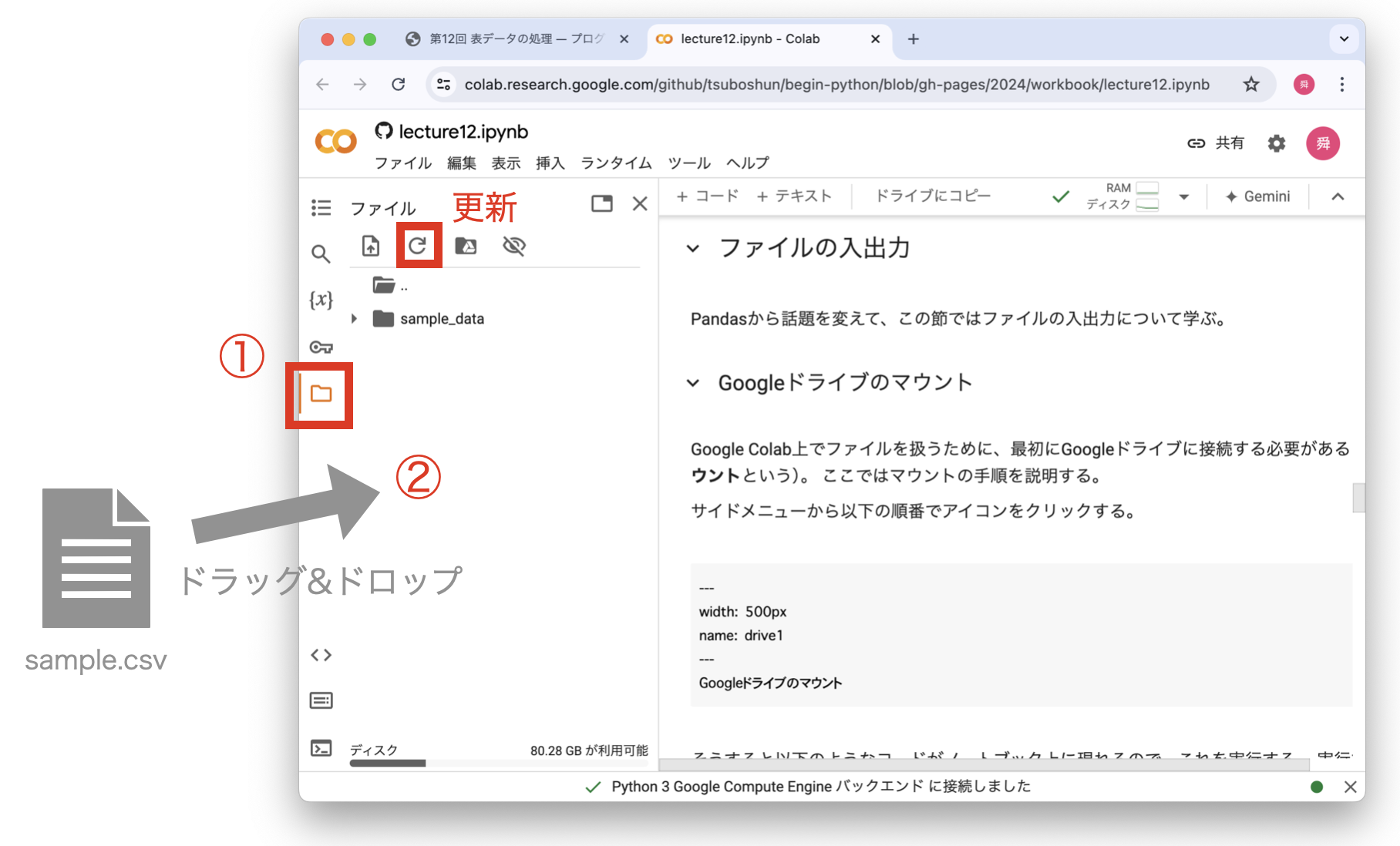
Fig. 23 Google Colabへのアップロード方法#
これでファイルがアップロードされた状態になる。
以下でプログラムを実行した際の出力ファイルも content フォルダ以下に配置される。もしコードを実行しても変化のない場合には、サイドメニューの更新ボタンを押す。
ファイルの読み込み#
さて、sample.csv の中身は以下の通りである。このように各要素がカンマ(,)で区切られて書かれたテキストデータをCSVファイルという(CSVは Comma-Separated Values の略)。
8,7,9,6,9 4,5,8,7,6 9,9,9,8,9 6,7,9,7,8
このファイルの中身は組み込み関数の open() を使って、次のように読み込むことができる。
path = "/content/sample.csv"
f = open(path, mode="r")
content = f.read()
print(content)
f.close()
open() 関数は、第一引数にファイルの存在する場所(パスという)、第二引数にモードを渡す。
パスは文字列で表し、フォルダを1つ下るごとに / で区切って content フォルダからの位置関係を表現する。
第二引数に渡している "r" は読み込みモードを表す。
open() 関数の返すファイルオブジェクト f に対して、read() メソッドを呼び出すと、ファイルの中身を文字列として取得できる。
最後に、開いたファイルオブジェクトを f.close() により閉じている。
read() メソッドの代わりに、for文により一行ずつ読み込むこともできる。
f = open(path, mode="r")
for line in f:
print(line)
f.close()
さて sample.csv の中身は各行が一人一人の学生、各列が何かしらのスコアを表していたとしよう(つまり学生4人・スコア5つ)。このときデータを2次元リストとして読み込めると、分析の際に便利である。次のコードにより、ファイルの中身を2次元リストとして読み込むことができる。
f = open(path, mode="r")
data = []
for line in f:
data.append(line.strip().split(","))
print(data)
f.close()
ここで各行の文字列 line について、まず strip() メソッドにより改行文字 \n (下のコラム参照)を取り除き、次に split(",") メソッドによりカンマで区切ってリストに変換している。例として、line にファイルの1行目 "8,7,9,6,9\n" が代入されたときの処理の流れを、以下に示す。
line.strip().split(",")
↓ line の指す値に置き換え
"8,7,9,6,9\n".strip().split(",")
↓ strip() メソッドの適用
"8,7,9,6,9".split(",")
↓ split() メソッドの適用
['8', '7', '9', '6', '9']
よって、data.append(line.strip().split(",")) は data.append(['8', '7', '9', '6', '9']) と同じことであり、これにより2次元リスト data の末尾に1次元リスト ['8', '7', '9', '6', '9'] が追加される。
注意点として、この時点では data の各要素は文字列型となっている。そこで分析前に整数型または浮動小数点数型に変換しておく。
for i in range(len(data)):
for j in range(len(data[i])):
data[i][j] = int(data[i][j]) # 小数を含むならfloat()
data
エスケープシーケンス
先ほど登場した \n は改行を表す特殊な文字列で、エスケープシーケンスの一つである。エスケープシーケンスの例として、他にはタブ入力を表す \t などがある。
ただし、Windows環境ではバックスラッシュ(\)が円記号(¥)として表示されることがあり、その場合、¥n、¥t などと入力する。
ファイルの書き込み#
読み込んだデータをもとに各生徒の平均スコアを求めて、ファイルに出力してみよう。
まず出力用のパスを入力とは別に設定する。open() 関数を書き込みモード("w") で呼び出し、書き込み用のファイルオブジェクト f を取得する。平均値の計算は、np.mean() 関数により行っている。そして結果を f.write() によりファイルに書き込んでいる。入力と同じように1行1学生となるように、最後に改行 \n を入れている。
ファイルへの書き込みを終えたら、f.flush()、f.close() を順に呼び出してファイルを閉じる。実は f.write() を呼び出した時点では、ファイルへの書き込みを予約した状態に過ぎず、OSの状態によっては実際の書き込みは後回しにされてしまう。f.flush() は、ファイルへの書き込みを確実に完了させる働きを持つ。
output_path = "/content/sample_mean.txt"
f = open(output_path, mode="w")
for lst in data:
mean = np.mean(lst)
f.write(f"{mean}\n")
f.flush()
f.close()
なお、ここで紹介した書き込み方法では、既に出力ファイルが存在する場合に、内容を上書きしてしまう。
そうではなく、既にある出力ファイルの末尾に追記したい場合には追記モード("a") を指定する。
そのほかファイルオブジェクトの使い方は書き込みモード("w")の場合と全く同じである。
練習3
上の例では、各学生の平均スコアを求めてファイルに出力した。これを参考に、平均スコアの代わりにスコアの標準偏差を求めてファイルに出力しなさい。ファイル名は sample_std.txt とすること。これは必須ではないが、可能なら小数は第3位を四捨五入して第2位までを求めなさい(第3回のf文字列の説明を参照のこと)。標準偏差は np.std() 関数により求めることができる。
ヒント: 学生は4人いるので、標準偏差も4つ求まることになる。sample_std.txt は次のような見た目になる。ヒントとして1行目の答えは 1.17 になる(四捨五入せずに1.16619…という解答でも正解とする)。
1.17
*
*
*
output_path = "/content/sample_std.txt"
f = open(output_path, mode="w")
for lst in data:
std = np.std(lst)
f.write(f"{std:.2f}\n")
f.flush()
f.close()
補足:NumPyやPandasを使った方法#
ファイルの中身を直接、配列やデータフレームとして読み込めると便利なため、NumPy、Pandasにそれ用の関数が用意されている。
ファイルの中身を配列として読み込むには np.loadtxt() 関数を使う。第一引数にファイルパスを指定し、キーワード引数 delimiter で区切り文字を指定する。
data = np.loadtxt(path, delimiter=",")
data
ファイルの中身をデータフレームとして読み込むには pd.read_csv() 関数を使う。第一引数にファイルパスを指定する。さらに列名の情報を含まないファイルの場合は、header=None を指定する。
df_sample = pd.read_csv(path, header=None)
df_sample
逆に配列やデータフレームの中身をファイルに書き込むには、np.savetxt() 関数や to_csv() メソッドを用いる。
np.savetxt("/content/sample_array.csv", data, delimiter=",")
df_sample.to_csv("/content/sample_df.csv", header=None, index=None)